![]()
Nie ma czegoś takiego jak nowy pomysł. To niemożliwe. Bierzemy zwyczajnie dużo starych pomysłów i wkładamy je do umysłowego kalejdoskopu. Kręcimy i w ten sposób powstają nowe, ciekawe kombinacje. Tak kręcimy i kręcimy, powstają kolejne kombinacje, ale to wciąż te same kawałki kolorowego szkła, które są z nami od wieków.
Sztuczna inteligencja – Artificial Intelligence, w skrócie: AI. Odmieniana przez wszystkie przypadki, budzi skrajne emocje: od bezkrytycznego zachwytu po strach, że wywróci nasz świat do góry nogami. Gdzieś pośrodku plasują się ci, którzy lubią AI za to, że wykonuje za nich żmudne prace i porządkuje chaos informacyjny. Ale korzystanie z niej ma swoją cenę. Jaką? Żeby się tego dowiedzieć, trzeba zajrzeć do środka czarnej skrzynki.
Nie chodzi jednak o to, by odtworzyć kolejne matematyczne przekształcenia (w pewnym momencie jest ich tyle, że przestają mieć sens dla obserwatora), ale o otwartą rozmowę, która pozwoli nam zrozumieć cel i podstawowe założenia konkretnego systemu wykorzystującego AI. Po co został wdrożony? Kto ma nad nim kontrolę? Jakie założenia na temat rzeczywistości przyjęli jego projektanci? Jakie się wiążą z tym ograniczenia? Jak wpływa na użytkowników?
AI nie jest samodzielnie podejmującym decyzje podmiotem. To ludzie decydują, do czego chcą wykorzystać tę technologię i jak ma ona działać. Przede wszystkim powinniśmy pilnować – i takie aspiracje mamy w Fundacji Panoptykon – żeby była wykorzystywana w interesie społeczeństwa i z poszanowaniem praw człowieka.
W tym opracowaniu:
- rozwiewamy mity i nieporozumienia narosłe wokół AI;
- opisujemy, jak wygląda proces projektowania systemów wykorzystujących AI i jaką rolę odgrywają w nim decyzje podejmowane przez ludzi;
- wyjaśniamy, jakie ograniczenia ma sztuczna inteligencja: w czym naprawdę może nam pomóc, a gdzie tworzy nowe ryzyka.
I. INTELIGENCJA AI
Inteligencja to zdolność adaptowania się do zmian
Według informatycznej definicji „sztuczna inteligencja” to określenie programu komputerowego, który zamiast wykonywać listę dokładnych instrukcji wykorzystuje zaawansowane modele statystyczne do tego, żeby rozwiązać zadanie. „Inteligencja” w tym przypadku oznacza, że program – na podstawie zbioru danych zawierającego przykłady zadań i poprawne odpowiedzi – sam znajduje występujące między nimi zależności (wzorce). Można powiedzieć, że program „inteligentnie” uczy się np. przypisywać obrazy psów i kotów do odpowiedniej kategorii zwierząt. Nie zmienia to faktu, że to ludzie piszą programy i dają im określone zadania do rozwiązania: czy to rozpoznawanie obiektów na zdjęciach, czy szacowanie ryzyka niespłacenia kredytu.
Słowem, które najczęściej pojawia się w kontekście AI, jest algorytm – inaczej zbiór instrukcji. Algorytmami są przepisy kulinarne, prawa w kodeksie karnym czy klucze odpowiedzi do zadań maturalnych. W programowaniu algorytm to instrukcja dla komputera; napisana w jednym z języków programowania pozwala maszynie wykonać zadanie, np. posortować zbiór liczb w kolejności od najmniejszej do największej czy wysłać użytkownikowi powiadomienie o 9 rano każdego dnia.
Algorytm uczenia maszynowego różni się od zwykłego algorytmu tym, że w wyniku jego działania powstają nowe reguły. Zwykły algorytm podpowie, jak dokończyć słowo, które użytkownik zaczął wpisywać na klawiaturze telefonu. Inteligentny algorytm zaproponuje kolejne słowa w oparciu o to, co użytkownik już napisał i w jakich zestawieniach te słowa są używane przez inne osoby (ignorując przy tym kulturowe normy, jak pokazuje poniższy przykład).
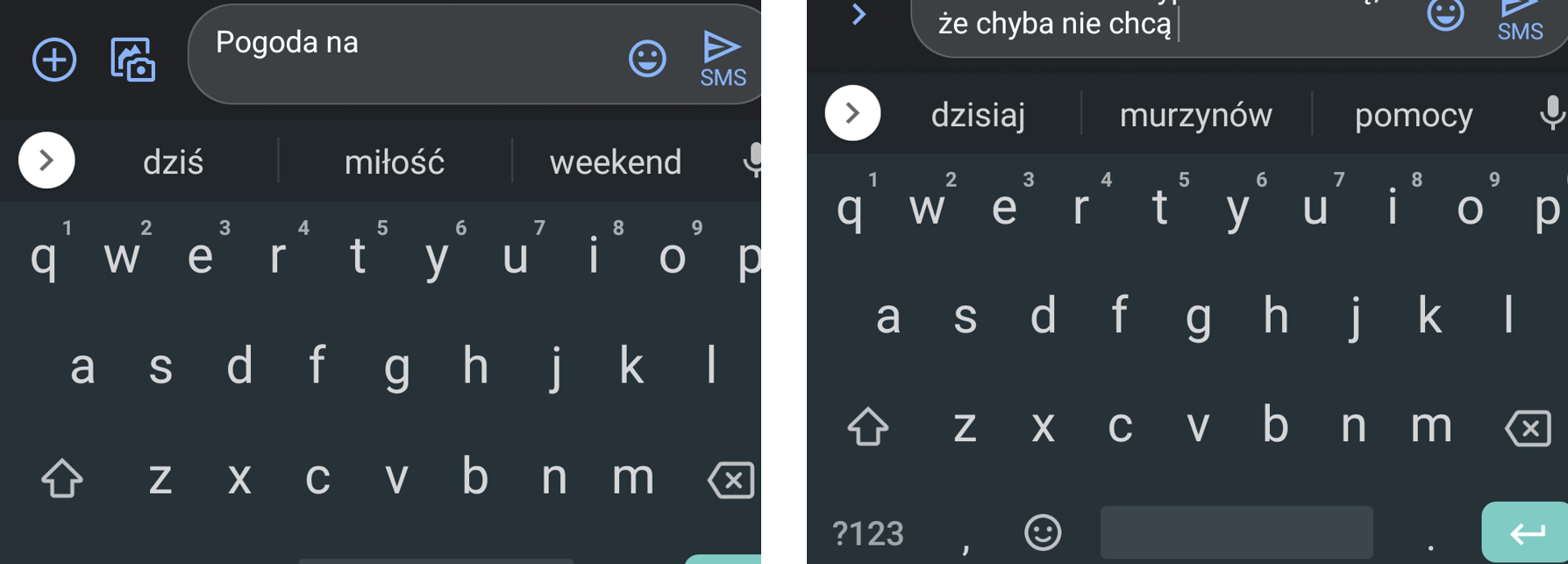
AI najlepiej sprawdza się w zadaniach polegających na wykrywaniu wzorów i prawidłowości (tzw. korelacji statystycznych) w dużych zbiorach danych. O ile coraz lepiej radzi sobie z prostymi wzorcami – np. w większości przypadków umie zaklasyfikować zdjęcie zwierzęcia do odpowiedniej kategorii czy wykryć na obrazie przejście dla pieszych – o tyle nieobiektywne i złożone zjawiska społeczne, zachowania człowieka i jego intencje czy interpretacja języka naturalnego (np. w komentarzach na Facebooku) nadal jej się wymykają.
Wraz z rozwojem nauki AI coraz częściej wspiera lub wręcz zastępuje człowieka w podejmowaniu decyzji w wielu sferach życia. Z różnym skutkiem, co pokazują np. trwające od lat eksperymenty z wykorzystaniem jej w medycynie. Systemy wykorzystywane w diagnostyce (m.in. przy analizie zdjęć rentgenowskich) statystycznie mają lepsze wyniki niż ludzie, ale wciąż robią wiele „głupich” błędów. Co więcej, porównywanie wyników ich pracy do pracy ludzi jest sztuczne, bo pomija fakt, że lekarz człowiek – w przeciwieństwie do maszyny – w trudnych przypadkach zasięgnie drugiej opinii. W praktyce może się też okazać, że system, który dobrze radził sobie w fazie eksperymentalnej, kiedy pracował na wyczyszczonych danych, po wdrożeniu w szpitalu daje nietrafne, a nawet niebezpieczne rekomendacje, jak miało to miejsce w przypadku Watsona firmy IBM, który nieraz zawiódł pokładane w nim nadzieje.
Największe kontrowersje budzi jednak wykorzystanie AI do przewidywania ludzkich zachowań. Ludzkie motywacje i działania trudno wtłoczyć w prawa statystyki. Skąd wiadomo, że dany kandydat sprawdzi się w pracy albo nie? Jakie jest prawdopodobieństwo, że osoba oskarżona o kradzież w oczekiwaniu na decyzję sądu ponownie naruszy prawo? Co musi się stać, żeby dziecko zeszło na złą drogę albo przeciwnie – wyszło na prostą? Nauki społeczne (psychologia, kryminologia) twierdzą, że zachowanie ludzi w dłuższym okresie wykazuje pewne prawidłowości i schematy. A więc możliwe jest oszacowanie prawdopodobieństwa, czy przestępczość na pewnym obszarze wzrośnie, czy spadnie. Zawsze będzie to jednak tylko przybliżenie, obarczone pewnym marginesem błędu i pomijające specyficzne cechy lub uwarunkowania konkretnych osób. Dlatego – z perspektywy tych ludzi, którzy wymykają się schematom albo już wcześniej stali się obiektem uprzedzeń i dyskryminacji – przewidywanie i modelowanie zachowań często oznacza błąd lub krzywdzącą decyzję.

II. AI NIE PODEJMUJE DECYZJI
Jeśli (…) zdecydujesz się postawić na całkowite wyeliminowanie wyników fałszywie negatywnych, twój algorytm może zacząć uznawać za podejrzane wszystkie skany piersi, które mu pokażesz. Osiągniesz stuprocentową czułość, co z pewnością uznasz za satysfakcjonujący wynik, będzie to jednak oznaczać, że ogromna liczba zdrowych kobiet zostanie niepotrzebnie poddana leczeniu. Powiedzmy zatem, że zdecydujesz się postawić na całkowite wyeliminowanie wyników fałszywie pozytywnych – wówczas twój algorytm przepuści przez sito wszystkie skany jako obrazy zdrowych piersi kobiecych, uzyskując stuprocentową swoistość. Cudownie! Chyba że jesteś jedną z tych kobiet z guzem w piersi, którą algorytm właśnie zignorował.
Znalezienie równowagi między czułością (trafnością w wykrywaniu np. stanu chorobowego, przy założeniu że eliminujemy wyniki fałszywie negatywne) a swoistością (trafnością w wykrywaniu np. stanu chorobowego, ale przy przeciwnym założeniu: eliminowania wyników fałszywie pozytywnych) algorytmów to kluczowy dylemat, przed którym stoją twórcy systemów wykorzystujących sztuczną inteligencję. Właśnie: twórcy systemów. Sztuczna inteligencja nie jest samodzielnie myślącym, podejmującym autonomiczne wybory bytem.
Decyzja, czy system ma być bardziej czuły, czy swoisty, należy do projektantów i właścicieli systemu. To oni wyznaczają cele, jakie ma realizować system, i określają to, jak zostanie skalibrowany. Czy będzie to system do wykrywania zmian nowotworowych, dystrybucji środków z pomocy społecznej czy predykcji w wymiarze sprawiedliwości? Czy dopuszczalne jest, że do programu leczenia niepotrzebnie zostanie zakwalifikowana zdrowa kobieta, czy to, że chora nie otrzyma leczenia? Czy system ma za zadanie nie pominąć nikogo potrzebującego, czy przede wszystkim nie zmarnować pieniędzy na kogoś, kto w rzeczywistości tej pomocy nie potrzebuje? Czy zalecić zwolnienie z aresztu osoby, jeśli istnieje choćby cień ryzyka, że złamie prawo, czy też zaryzykować trzymanie w nim osoby, która nie popełniłaby przestępstwa? Nawet w systemach wykorzystujących tzw. głębokie uczenie maszynowe (deep learning) te fundamentalne decyzje podejmują ludzie. Programowi (np. sieci neuronowej) pozostaje szukanie odpowiedzi na pytanie, jak postawione mu cele zrealizować.
Czy AI nas zniszczy?
Sztuczna inteligencja może być zarówno najlepszą, jak i najgorszą rzeczą, która kiedykolwiek przydarzyła się ludzkości – mówił Stephen Hawking. Badaczka nowych technologii Aleksandra Przegalińska w książce Sztuczna inteligencja. Nieludzka, arcyludzka koncentruje się na potencjale AI, chociaż dostrzega też jej ograniczenia:
(…) maszyna ma swoje funkcje, w których jest znakomita, na przykład inteligencję obliczeniową (…). Nie będziemy się z nią ścigać, bo to byłoby bez sensu (…). Dlaczego mielibyśmy nie korzystać z kalkulatora, skoro liczenie idzie nam wolniej niż temu urządzeniu? Jednak w wielu innych kwestiach – w szeroko rozumianej integracji i inteligencji społecznej, we współpracy, w emocjonalności, kreatywności etc. – maszyny są w porównaniu z nami ułomne.
Robi też wyraźne rozróżnienie między inteligencją a świadomością:
Oczywiście można zdefiniować inteligencję tak, aby wyszło na to, iż jedynie ludzie ją posiadają. Ale to chyba błędny kierunek. Dla mnie głęboka sieć neuronowa, która jest w stanie wymyślić nowy sposób gry w go, jest przykładem inteligencji. (…) Alpha Go gra zupełnie inaczej niż ludzie, którzy kiedykolwiek grali w tę grę. Nawet gdyby grał zwyczajnie, tak jak ludzie, i starał się wygrywać, to już byłoby dużo, ale on gra inaczej. (…) Alpha Go, a raczej jego unowocześniona wersja – Alpha Zero, gra najlepiej na świecie, ale nie wie, że jest mistrzem. Trudno mi sobie wyobrazić, aby taki system chciał zagrać w go sam z siebie – żeby robił cokolwiek z własnej, czystej ciekawości. To cecha ludzka – wyjaśnia.
Czy to oznacza, że – upraszczając – AI, nawet jeśli kogoś zniszczy, zrobi w wyniku zaniedbań człowieka?
III. MIT CZARNEJ SKRZYNKI
Wszystko, co ma związek z AI, powinno być wyjaśnialne, sprawiedliwe, bezpieczne i opatrzone informacją o swoim pochodzeniu – wtedy nie będzie wątpliwości, skąd wzięło się dane zastosowanie AI i czemu ono służy.
„Czarna skrzynka” – kolejne pojęcie, które nierozerwalnie kojarzy się z AI – może oznaczać zarówno takie systemy, których wewnętrzne zasady działania są niejasne lub niezrozumiałe dla człowieka (np. wykorzystujące sieci neuronowe, które wykonują tyle operacji obliczeniowych, że odtworzenie obliczeń nie pomoże w zrozumieniu tego, co się dzieje w środku), jak i takie, których zasady pozostają ukryte ze względu na tajemnicę handlową lub z obawy, że człowiek mógłby próbować je przechytrzyć lub oszukać. Zdarzają się też oczywiście przypadki, w których mamy do czynienia z mieszanką tych wszystkich czynników – niejako potrójną czarną skrzynką.
Zdaniem Komisarz Praw Człowieka wszędzie tam, gdzie technologia może mieć wpływ na prawa człowieka, zasady działania systemu nie powinny być ukrywane pod pretekstem chronienia własności intelektualnej. A jeśli pojawia się obawa, że człowiek może próbować taki system oszukać, warto ją traktować jako sygnał ostrzegawczy: czy czasem system nie został błędnie zaprojektowany lub nie opiera się na dyskryminujących założeniach? Na przykład: jeśli system wspiera dystrybucję środków społecznych albo decyzje sędziów, zasady jego działania bezwzględnie muszą być jawne. Jeśli dzięki temu można ten system przechytrzyć (tj. wpłynąć na to, jak AI sklasyfikuje daną osobę i jaką wyda rekomendację), to po prostu oznacza, że został on źle zaprojektowany (np. jest zbyt wrażliwy na małe różnice w danych) i nie powinien być wykorzystywany.
Nawet jeśli mamy do czynienia z „czarną skrzynką” w sensie technicznym – tj. gdy system wykorzystuje głębokie uczenie maszynowe i bez doktoratu z matematyki trudno zrozumieć zasady jego działania, nie mówiąc o prześledzeniu dokładnego przebiegu procesu uczenia – zawsze możemy się domagać wyjaśnienia zasad i założeń, jakie przyjęto przy jego projektowaniu. Jakim celom służy? Na jakich danych został wytrenowany? Jaki model statystyczny wykorzystuje? Jakie ma ograniczenia? Jak wypada w testach? Jaki jest zakres jego stosowalności (czyli na jakich problemach można go stosować, a na jakich nie)?
Jak wyjaś nić działanie AI?
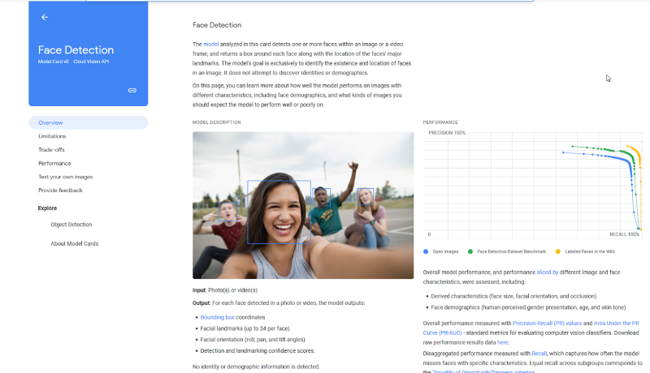
Firma Google przygotowała modelowe wyjaśnienia dla swoich systemów rozpoznawania twarzy i obiektów na zdjęciach. Ze strony dowiemy się nie tylko, jakie zadanie realizuje konkretne narzędzie (np. wykrywa twarze na zdjęciach i oznacza je kwadratem), ale też jakich danych potrzebuje, jakie ma ograniczenia (np. nie wykryje twarzy na obrazach o niskiej rozdzielczości, nie nadaje się do szacowania liczebności tłumu) i na jakiej architekturze się opiera (konwolucyjnej sieci neuronowej MobileNet). Dostępna jest też informacja o skuteczności narzędzia (performance) i jego dokumentacja.
IV. LEKCJA ROZPOZNAWANIA AI
Sztuczną inteligencję można wykorzystać w każdym urządzeniu czy usłudze, żeby poprawić ich działanie. Warto myśleć o niej jak o przyprawie, a nie o samodzielnym daniu. Sama nie jest szczególnie warta uwagi, ale dodana do posiłku – może całkowicie zmienić jego smak.
Dodajmy, że nieumiejętnie użyta może go też popsuć.
Moda na AI sprawiła, że producenci i dostawcy usług z niemal każdej branży chcą ją umieścić w swoich produktach albo przynajmniej w ich reklamie – niezależnie od tego, czy rzeczywiście ją wykorzystują. Celują w tym producenci urządzeń domowych (poza anegdotycznymi „inteligentnymi” lodówkami pod strzechy trafiły już „inteligentne” głośniki, odkurzacze i pralki), ale też kosmetyków, nie wspominając o zabawkach (które są co najwyżej podłączone do Internetu), czy np. doniczkach (które na to hasło przyciągają zabieganych mieszczuchów, ale z AI nie mają w rzeczywistości nic wspólnego). Zdarza się jednak, że firmy wykorzystujące wyrafinowane algorytmy uczenia maszynowego nie chcą się tym faktem chwalić, żeby nie przestraszyć lub nie zniechęcić ludzi, którzy będą przez taki system oceniani (np. podczas oceny wiarygodności kredytowej czy rekrutacji).
Po czym rozpoznać, czy mamy do czynienia ze sztuczną inteligencją – czyli programem komputerowym wykorzystującym statystyczny model zbudowany z użyciem uczenia maszynowego – a nie zwykłym algorytmem albo jedynie pustym chwytem marketingowym? Z pomocą przychodzi schemat przygotowany przez Karen Hao dla MIT Technology Review (poniżej).
Chociaż popularne wyobrażenie AI to robot mówiący ludzkim głosem, na co dzień mamy z nią do czynienia w zupełnie innym wydaniu. Spotykamy ją między innymi:
- Szukając informacji w Internecie
Najpopularniejsza wyszukiwarka internetowa świata w odpowiedzi na wpisaną (lub wypowiedzianą na głos) frazę lub słowo zwraca listę stron. Wyniki wyszukiwania są posortowane w taki sposób, żeby użytkownik z jak największym prawdopodobieństwem kliknął w jeden z linków. Ich kolejność zależy nie tylko od tego, czy dana strona odpowiada wpisanej frazie, ale również od jej popularności wśród innych użytkowników. Google bierze też pod uwagę język i lokalizację osoby zadającej pytanie oraz historię jej wcześniejszych wyszukiwań.
Przy okazji wyszukiwania informacji użytkownikowi wyświetlają się także inteligentnie dobrane reklamy. Podobnie jak w przypadku samej wyszukiwarki zadaniem Google Ads jest wyświetlenie takich reklam, w które z największym prawdopodobieństwem kliknie konkretny użytkownik.
- Słuchając muzyki i oglądając filmy
Algorytmy rekomendujące kolejne filmy na YouTubie mają za zadanie jak najdłużej utrzymać uwagę użytkowników i zachęcać ich do konsumowania kolejnych treści (a wraz z nimi – personalizowanych reklam). O tym, co zasugerować do obejrzenia konkretnej osobie, system „decyduje” w oparciu o historię obejrzanych wcześniej filmów (i filmów obejrzanych przez inne osoby), a także o wszelkie inne dane, jakie Google zebrał na temat użytkownika z różnych źródeł: od historii wyszukiwania i treści wysłanych maili po odwiedzane strony w sieci i wszystko, co się na nich działo.
AI obecna jest też w systemach rekomendacyjnych w serwisach Spotify i Netflix. Ta druga platforma wykorzystuje AI nie tylko po to, żeby jak najdłużej utrzymać uwagę użytkowników, ale też pod kątem swoich przyszłych produkcji. Może też wykorzystywać ją, żeby wpływać na zachowania użytkowników.
- Scrollując Facebooka
Algorytm dobierający treści i reklamy wyświetlane na Facebooku wpływa na dietę informacyjną, nastrój i relacje społeczne miliardów ludzi na ziemi. Algorytm odpowiada za posortowanie postów (zarówno tych pochodzących z sieci społecznościowej, jak i treści sponsorowanych) w taki sposób, żeby jak najdłużej utrzymać uwagę użytkowników i użytkowniczek. Analizuje wszystkie informacje, które Facebook zgromadził lub wydedukował na temat konkretnej osoby, a także jej reakcje na treści. Jak wykazały m.in. śledztwa dziennikarskie Guardiana i niezależne projekty badawcze, w grę wchodzą także bardzo wrażliwe dane: od relacji intymnych i załamań nerwowych po ukryte pragnienia i oczekiwane zmiany życiowe.
- Pytając telefon o drogę albo prosząc go o opowiedzenie żartu
Zadaniem asystentów jest przełożenie poleceń głosowych na konkretne działanie urządzenia lub usługi. Te systemy umożliwiają przełożenie mowy na różne polecenia, które ma wykonać komputer, np. uruchomić mapę, wskazać adres docelowy, kliknąć start lub wyszukać w sieci dowcip i go odczytać.
- Kiedy chcesz dokonać autodiagnozy na koronawirusa
Na stronie pacjent.gov.pl można spotkać Watsona, system firmy IBM, który „udziela odpowiedzi dotyczących koronawirusa”, czyli dopasowuje podane przez użytkownika informacje do jednej lub kilku przygotowanych wcześniej odpowiedzi. Jak sam informuje: „najlepiej rozumie pytania krótkie i dotyczące jednego zagadnienia”.
Watson powstał na początku XXI w. jako pierwszy program komputerowy trenowany do odpowiadania na pytania zadane w języku naturalnym. W 2011 r. zwyciężył z ludźmi w turnieju Jeopardy!, od 2013 r. jest stosowany w medycynie – chociaż z uwagi na kosztowne błędy, które ma na swoim koncie (a konkretnie niebezpieczne i nietrafne propozycje terapii onkologicznych), głównie do wąsko określonych zadań (np. analizy obrazowych wyników badań).
V. O POWSTAWANIU AI
Największe niebezpieczeństwo związane ze sztuczną inteligencją to to, że ludzie zbyt wcześnie uznali, że ją rozumieją.
Sztuczna inteligencja powstaje w wyniku modelowania statystycznego, czyli opisywania zależności, jakie da się zaobserwować w rzeczywistości, w postaci formuł matematycznych. Statystyka pojawia się tu nie bez powodu: model opisuje rzeczywistość w przybliżeniu, a więc zawsze z pewnym marginesem błędu.
Na przykład funkcja liniowa s = vt pozwala wyliczyć przebytą drogę (s) w t czasu przy prędkości v i zobaczyć, że przy wyższej prędkości droga przebyta w tym samym czasie będzie dłuższa. Model statystyczny wykorzystujący uczenie maszynowe dostaje od człowieka zagadnienie, jakie ma rozwiązywać. Może być nim rozpoznanie obiektu na zdjęciu (Captcha), wygranie z człowiekiem w go (Alpha Go), rekomendacja następnego filmu (YouTube) czy ocena prawdopodobieństwa recydywy (COMPAS). Model nie dostaje jednak na wejściu informacji o istniejących zależnościach. Jego zadaniem jest zaobserwowanie tych zależności i zapisanie ich w postaci formuł matematycznych, a następnie – w oparciu o poczynione obserwacje – rozwiązywanie podobnych zagadnień.
Wszystkie modele statystyczne są uproszczeniem i przez to nie dają 100% prawdziwych odpowiedzi. Sprawdzają się w szacowaniu prawdopodobieństwa wystąpienia różnych zdarzeń i zjawisk, ale jeśli u podstaw konkretnego modelu leżą błędne założenia, jego szacunki również będą dalekie od rzeczywistości. Warto też pamiętać, że korelacje statystyczne (jak ta między wydatkami na naukę i technologię a liczbą samobójstw przez powieszenie czy liczbą filmów z Nicolasem Cage’em a liczbą utonięć w basenach) bywają zupełnie przypadkowe i wcale nie muszą się przekładać na związek przyczynowo-skutkowy.
Uczenie maszynowe w sieci neuronowej
Najbardziej popularna forma uczenia maszynowego (nadzorowane uczenie maszynowe) polega na doskonaleniu modeli statystycznych w oparciu o duże zbiory danych, zawierające zadania i ich rozwiązania. Na bazie danych treningowych model statystyczny „uczy się” zależności między zadaniami a rozwiązaniami. Prostsze modele, m.in. regresja liniowa, od dziesięcioleci są wykorzystywane w medycynie, ekonomii, fizyce i socjologii. Dopiero od niedawna o uczeniu maszynowym mówi się przede wszystkim w kontekście sieci neuronowych – złożonych modeli statystycznych, wzorowanych na strukturze mózgu, ale działających na zupełnie innych zasadach.
Siecią neuronową jest np. GAN (generative adversarial network), opracowana przez Iana Goodfellowa w 2014 r. i wykorzystywana do tworzenia nowych obrazów na podstawie bazy istniejących, czy OCR (optical character recognition) wykorzystywany do rozpoznawania tekstu (np. w bibliotekach cyfrowych, takich jak Project Gutenberg, ale też w systemach rozpoznawania tablic rejestracyjnych, takich jak trójmiejski Tristar.
Sieć neuronowa, która ma za zadanie nauczyć się odróżniać na zdjęciach wilki od psów, jako dane treningowe otrzymuje zdjęcia tych zwierząt oraz informację, na których jest pies, a na których wilk. Następnie szuka istotnych zależności (np. pies ma taką długość uszu, a wilk inną). Do wytrenowania sieci neuronowej potrzebna jest odpowiednio duża liczba przykładów (w przypadku rozpoznawania obiektów na zdjęciach – nawet setki tysięcy), o dużej różnorodności (różne rasy psów, różne oświetlenie czy roślinność), które pozwolą wykryć najdrobniejsze zależności. Zbyt mała liczba i różnorodność zdjęć może prowadzić do nietrafionych obserwacji, np. takich, że pies zawsze występuje na tle trawy, a wilk – śniegu (jak w eksperymencie badaczy z uniwersytetu w Waszyngtonie).
Jeśli model zostanie wytrenowany na reprezentatywnych, różnorodnych i dobrze opisanych danych, prawdopodobnie poprawnie wykona zadanie także pracując na nowych (dla siebie) danych (np. trafnie wskaże, czy na innym, wcześniej nieanalizowanym zdjęciu znajduje się pies, czy wilk). Wysokiej dokładności można jednak oczekiwać tylko wtedy, kiedy system pracuje na danych o podobnej strukturze do danych treningowych. Jeśli np. zmienią się proporcje rozpoznawanych obiektów (tym razem system będzie oceniał głównie zdjęcia wilków, chociaż wytrenowany był na zdjęciach w połowie wilków, a w połowie psów), jego dokładność spadnie. Jeśli zaś w procesie trenowania model zaobserwował nie zawsze prawdziwe zależności i nie zostało to skorygowane przez nadzorującego uczenie maszynowe człowieka, odpowiedzi będą nietrafione (lub trafione przypadkowo, jeśli wciąż system będzie dostawał do oceny zdjęcia wilków na śniegu i psów na trawie).
Większość algorytmów wykorzystujących uczenie maszynowe jest na tyle elastyczna, że radzi sobie z niewielkimi odchyleniami od zaobserwowanych zależności. Ale co się dzieje, kiedy pojawiają się nowe dane, kompletnie odbiegające od tego, z czym miały do czynienia wcześniej? Podobnie jak w przypadku modelu wytrenowanego na niewystarczająco różnorodnych zdjęciach psów i wilków – będą dawały błędne wyniki.
Ten problem dotknął ostatnio sklep Amazona, kiedy na początku pandemii koronawirusa maseczki i środki czystości zajęły miejsce ładowarek i etui do telefonów wśród najpopularniejszych produktów. Nagła i duża zmiana w rozkładzie danych (zachowaniu konsumentów) sprawiła, że algorytmy odpowiadające za wyłapywanie oszustw, marketing czy zaopatrzenie magazynów dostały czkawki (np. poszybowały ceny niektórych produktów). Ten przypadek pokazuje, że nie wystarczy raz zaprojektować system i kliknąć „start”. Trzeba przez cały czas czuwać nad jego działaniem, zwłaszcza kiedy diametralnie zmieniają się okoliczności.
Projektanci AI nie muszą tworzyć modeli statystycznych od zera. Zazwyczaj wykorzystują modele opracowane przez naukowców lub inżynierów zatrudnianych przez duże firmy technologiczne (np. Google czy Microsoft) albo renomowane uczelnie (np. MIT). Wiele takich modeli już trafiło do domeny publicznej, a więc każdy może z nich skorzystać (dostępne są np. w bibliotece scikit-learn). Prawo do skorzystania z innych, które nadal są chronione jako własność intelektualna, można kupić. Dzięki temu można łatwiej i taniej tworzyć nowe systemy. Pojawiają się jednak też pytania o zaufanie do gotowego modelu i odpowiedzialność za zaszyte w nim błędy. Poza tym, mimo że gotowy model nie wymaga trenowania od zera, zawsze konieczne jest jego wykalibrowanie i przetestowanie na danych treningowych.
Skąd analitycy biorą dane do trenowania i testowania modeli statystycznych? W praktyce można kupić gotową bazę, zatrudnić ludzi do jej stworzenia albo pozyskiwać dane bezpośrednio od użytkowników. Ten ostatni sposób bywa kontrowersyjny, zwłaszcza kiedy użytkownicy nie wiedzą, że biorą udział w trenowaniu sztucznej inteligencji (jak miało to miejsce np. w przypadku systemu rozpoznawania twarzy firmy IBM, który uczył się na fotografiach z Flickra, czy Captchy, którą trenujemy, zaznaczając fragmenty zdjęcia, gdzie występuje sygnalizacja świetlna i hydranty).
Algorytm ś lepy na cechy mniejszoś ci
O tym, jak duże znaczenie dla późniejszego działania systemu ma jakość danych treningowych, świadczą choćby głośne porażki systemów rozpoznawania twarzy. W tej dziedzinie często dochodzi do dyskryminacji lub zwyczajnych błędów w stosunku do osób, których cechy były rzadziej reprezentowane w bazach danych, na których uczyły się algorytmy. Według raportu National Institute of Standards and Technology przy rozpoznawaniu twarzy czynniki takie jak pochodzenie czy kolor skóry realnie wpływają na wzrost wskazań fałszywie pozytywnych, zwiększając ich odsetek od 10 do nawet 100 razy. Pokrzywdzone są także kobiety, w przypadku których wskaźnik false positives jest od 2 do 5 razy większy niż w przypadku mężczyzn.
Historyczne nierówności zapisane w danych ujawniły się też w amerykańskim projekcie COMPAS, który zyskał rozgłos za sprawą śledztwa Julii Angwin (więcej o sprawie piszemy niżej). Algorytm miał za zadanie szacować ryzyko recydywy, przemocy i niestawienia się w sądzie osób oskarżonych o popełnienie przestępstwa. W założeniu ta sztuczna inteligencja miała korygować uprzedzenia (zwłaszcza uprzedzenia rasowe) w decyzjach podejmowanych przez sędziów, jednak ostatecznie algorytm, nakarmiony historycznymi danymi (które utrwalały nieproporcjonalny nadzór nad nie-białymi osiedlami i wynikające z niego częstsze areszty), odtworzył uprzedzenia sędziów i błędnie zawyżał ryzyko ponownego popełnienia przestępstwa właśnie w przypadku osób czarnych.
Skuteczność modelu statystycznego, który ma za zadanie rozwiązać problem nierozwiązywalny (albo obiektywnie trudny) dla człowieka, w ogromnej mierze zależy od danych, na których został wytrenowany. Nawet dobrze zaprogramowany model, jeśli zostanie nakarmiony niereprezentatywnymi danymi, wygeneruje fałszywe wyniki. W przypadku braku odpowiednich danych częstą, choć kontrowersyjną praktyką jest korzystanie z informacji pośrednio związanych z analizowanym problemem. Może to prowadzić do błędów i przypadków dyskryminacji, jak w przypadku systemu stosowanego w amerykańskich szpitalach. System, który miał za zadanie zakwalifikowanie potrzebujących pacjentów do specjalistycznych programów leczenia, brał pod uwagę koszty leczenia danej osoby w ciągu roku (przy braku lepszych danych na temat stanu zdrowia). Decydując się na ten zbiór danych, projektanci systemu nie uwzględnili, że w Stanach Zjednoczonych wydatki na leczenie osób czarnoskórych są statystycznie niższe niż osób białych cierpiących równie poważnie na tę samą chorobę. W efekcie system powielił schemat wynikający z nierówności ekonomicznych, klasyfikując osoby czarnoskóre jako „mniej chore”, niż były w rzeczywistości.
Paradoksy AI
Przemysław Biecek, kierownik warszawskiego MI2DataLab, zauważa:
Paradoksem w trenowaniu systemów AI jest to, że znacznie łatwiej się taki system buduje niż testuje. Proces budowy modeli jest w dużym stopniu zautomatyzowany. Wymaga on oczywiście dużo danych, dużo mocy obliczeniowej i umiejętności, ale do budowy modeli mamy dobre narzędzia. Nie mamy za to wystarczających procedur postępowania, narzędzi ani metod matematycznych do przewidywania długofalowych konsekwencji.
Twórcy modeli wystawieni są na różne pokusy. Mogą być przekonani, że ich modele są świetnie sprawdzone (przez nich) a wszystkie ryzyka zostały przewidziane (przez nich). Krótka historia rozwoju systemów AI uczy nas jednak, że przewidywanie długofalowych konsekwencji wdrażania systemów AI jest bardzo trudne. A ponieważ te konsekwencje mogą w sposób masowy oddziaływać na dużą część społeczeństwa, więc też do przewidywania tych konsekwencji potrzebujemy interdyscyplinarnych zespołów.
Z tych samych powodów, dla których tak trudno jest zaprojektować sprawiedliwy system oceny stanu zdrowia lub ślepy na społeczne stereotypy system szacowania ryzyka w wymiarze sprawiedliwości, ogromnym wyzwaniem jest wykorzystywanie AI do analizy zjawisk wcześniej niezbadanych. Na przykład w przypadku badań nad szczepionką na koronawirusa AI może pomóc w testowaniu nowych hipotez czy symulacji zachowania konkretnych białek, w ten sposób przyspieszając pracę naukowców. Ale pewne jest, że nie zastąpi ich ani nie znajdzie za nas rozwiązania nowego problemu, jak można by się spodziewać po sensacyjnych nagłówkach.
VI. NA TROPIE UKRYTYCH KOSZTÓW
Wykorzystywanie algorytmów do opisywania świata rzeczywistego nie zawsze pomaga. Zwłaszcza jeśli obecny świat rzeczywisty ukształtowały stulecia uprzedzeń.
Entuzjaści AI wskazują, że każdy człowiek ma uprzedzenia, a maszyny można pod tym względem poprawić. Krytycy – że systemy wykorzystujące AI nader często powielają uprzedzenia swoich projektantów. Jak jest w rzeczywistości? Sam fakt, że sztuczna inteligencja „uczy się” wzorców ludzkich zachowań i przewidywania tego, co nastąpi, w oparciu o dostarczone jej dane, jeszcze nie gwarantuje racjonalności, a tym bardziej sprawiedliwości rozstrzygnięć.
Projektanci systemów mogą tak dobierać cele działania systemu i dane treningowe, żeby nie powielać społecznych uprzedzeń, ale w praktyce jest to trudne. To, czy narzędzie będzie działało w sposób dyskryminujący, zależy też od tego, kim są i jakie założenia na temat rzeczywistości przyjmą jego twórcy oraz czy włożą wysiłek w to, by skorygować skrzywienia przenoszone w danych. Ryzykowne jest zwłaszcza ślepe zaufanie do statystyki. Przykład? Statystycznie kobiety zarabiają mniej niż mężczyźni, a na wydziałach pedagogicznych studiuje więcej kobiet. To jednak nie powód, by system rekrutował mężczyzn na lepiej płatne stanowiska albo odrzucał podania mężczyzn, których powołaniem jest nauczanie. Wreszcie: bardzo dużo zależy od tego, w jaki sposób i z jakimi intencjami narzędzie zostanie ostatecznie wykorzystane – nawet dobrze zaprojektowaną technologię można przecież wykorzystać po to, by dyskryminować i wykluczać ludzi ze względu na określone cechy.
Jak algorytm Amazona nauczył się mizoginii
W 2014 r. Amazon pracował nad rozwiązaniem, którego zadaniem miała być selekcja kandydatów i kandydatek do pracy. Maszyna miała być wolna od uprzedzeń, którymi kierowali się menedżerowie przeglądający CV. Problem jednak tkwił w danych dotyczących rekrutacji, na których została wytrenowana: zaprzęgnięty do pracy model statystyczny w danych z poprzedniej dekady wykrył, że zatrudniano głównie mężczyzn. Skoro firma preferowała mężczyzn, model priorytetowo traktował te CV, które zawierały agresywny język (np. execute), którego częściej używają mężczyźni. Mniej punktów otrzymywały też aplikacje, w których pojawiały się nazwy żeńskich uczelni. Algorytm niejako dostosował się do kultury firmy i do rozwiązania zadania zastosował te same reguły, które (mniej lub bardziej świadomie) przez lata stosowali menedżerowie odpowiedzialni za rekrutację.
Czy jesteśmy skazani na uprzedzone algorytmy? Niska jakość danych, trenowanie systemu na danych nieadekwatnych do celu, nieprawidłowo lub nierealistycznie określony cel przewidywania to najczęściej wskazywane przyczyny uprzedzonych decyzji AI. Przy czym nie można zapominać, że te decyzje podejmują właściciele i twórcy systemów, a nie sama sztuczna inteligencja. Nie jest to więc wina programu komputerowego ani modelu statystycznego, ale człowieka, który go stworzył. To również człowiek decyduje o tym, by mimo ograniczeń AI użyć jej do rozwiązywania problemów, w których pojawia się ryzyko dyskryminacji lub wykluczenia.
Moja praca polega na tłumaczeniu priorytetów z języka biznesu na język danych. (…) Pojawiają się przy tym nie tylko pytania etyczne, ale też pytania o to, co jest priorytetem. Nie da się jednocześnie zminimalizować wskazań fałszywie pozytywnych, zmaksymalizować trafności i zminimalizować wskazań fałszywie negatywnych. Co poświęcić? – mówi Cathy O’Neil, autorka Broni matematycznej zagłady, pytana o te trudne decyzje.
Dylematy twórców AI doskonale ilustruje przypadek systemu COMPAS, wykorzystywanego przez amerykańskie sądy do szacowania prawdopodobieństwa ponownego popełnienia przestępstwa (tzw. recydywy) przez osoby już raz oskarżone i aresztowane. Twórcy systemu obiecywali, że zastosowanie „racjonalnego” algorytmu pozwoli na ograniczenie przypadków, w których aresztowanie jest bezzasadnie przedłużane, i wyrównanie szans osób wcześniej dyskryminowanych. Decyzje podejmowane z wykorzystaniem COMPAS-u miały być bardziej trafne, spójne i obiektywne niż te, które podejmowali sędziowie. Wiązano z nim nadzieję zmniejszenia nierówności rasowych i socjoekonomicznych, które trawią amerykańskie społeczeństwo. Śledztwo zespołu dziennikarki Julii Angwin pokazało jednak, że wskazania algorytmu również były stronnicze – na niekorzyść czarnych oskarżonych, ale też młodszych podsądnych i kobiet.
COMPAS został opracowany przez przez firmę Northpointe, a szczegóły jego budowy pozostają tajne. Dziennikarka przestudiowała zatem podręcznik użytkowania, w którym twórcy opisali zastosowanie systemu i szczegóły całego projektu i na podstawie publicznie dostępnych danych odtworzyła ich system. Wraz z zespołem Angwin przeanalizowała też, jakie etykiety COMPAS przyznał 10 tys. oskarżonych w hrabstwie Broward na Florydzie w trzech kategoriach: „ryzyko recydywy”, „ryzyko przemocy” i „ryzyko niestawienia się w sądzie”, w skali od 1 (najniższe) do 10 (najwyższe). Wreszcie – jej zespół sprawdził, jak naprawdę potoczyła się historia tych osób w ciągu dwóch lat od aresztowania.
Przewidywania COMPAS-u okazały się dalekie od rzeczywistości. „Ryzyko recydywy” oszacował poprawnie w ok. 60% przypadków, podczas gdy wskazania dotyczące „ryzyka przemocy” były trafne tylko w 20%. Analiza pokazała też, że chociaż poprawne wskazania są tak samo częste w stosunku do białych, jak i czarnych oskarżonych, to model częściej zawyża ryzyko „recydywy” (a więc myli się) w przypadku osób czarnych. Okazało się, że twórcy algorytmu upewnili się, że algorytm popełniał błędy tak samo rzadko w przypadku osób czarnoskórych i białych, jednak nie uwzględnili, że istnieją dwa typy błędów popełnianych przez algorytm, i że błędy te mają zupełnie inne konsekwencje. Pro Publica pokazała, że algorytm popełniał błędy typu I (false positives) o wiele częściej w przypadku osób czarnoskórych, a błędy typu II (false negatives) w przypadku białych. W konsekwencji osoby czarnoskóre, niesłusznie oflagowane jako ryzykowne, niepotrzebnie pozostawały dłużej w areszcie. Najważniejszym czynnikiem ryzyka okazał się jednak młody wiek – ważniejszym nawet niż wcześniejsza historia naruszania prawa, przewidywana przyszłość, rasa czy płeć oskarżonego czy oskarżonej.
Publikacja artykułu pt. There’s software used across the country to predict future criminals. And it’s biased against blacks (Oprogramowanie przewiduje, czy ktoś zostanie przestępcą. I jest ono uprzedzone w stosunku do czarnych) wywołała burzę. Dyskutowano nie tylko o tym, czy algorytm może być bardziej sprawiedliwy niż ludzie, ale przede wszystkim o stosunkach społeczno-ekonomicznych panujących w Stanach Zjednoczonych, które sprawiają, że do więzień trafia więcej czarnych Amerykanów niż białych. Ten aspekt informatycy praktycznie zignorowali, skupiając się głównie na tym, czy da się zrobić bardziej sprawiedliwy algorytm. W debacie publicznej pojawiła się jednak ważna konkluzja: algorytm wytrenowany na „skrzywionych” danych musi dać podobnie „skrzywione” wyniki. Krytyka COMPAS-u zogniskowała się na decyzji twórców, którzy musieli zdawać sobie sprawę z ryzyka dyskryminacji, jakie niósł ze sobą ich system, ale zaakceptowali je.
Cała historia mogłaby wcale nie wyjść na jaw, bo zarówno sam model, jak i informacja o tym, na jakich danych został wytrenowany, pozostają chronione tajemnicą firmy, która go stworzyła. Zespół Julii Angwin – w oparciu o względnie szczegółowe dane opublikowane w podręczniku użytkowania, literaturę metodologiczną i kryminologiczną, dostępne analizy algorytmu i dane pozyskane z sądów na Florydzie – zbudował jednak własny, możliwy do zinterpretowania model statystyczny i wytrenował go do takiego samego zadania, jakie realizował COMPAS. Ten eksperyment pozwolił dziennikarzom odkryć m.in. to, że o takim, a nie innym wskazaniu COMPAS-u decydowały przede wszystkim wiek, kolor skóry i płeć aresztowanych osób. Co ciekawe, informacja o kolorze skóry nie znajdowała się w zbiorze analizowanych danych, jednak model mógł ją łatwo wywnioskować z innych zmiennych (m.in. kwestionariusza dotyczącego sąsiedztwa, z którego pochodziła osoba podejrzana).
Fundamentalne pytanie o to, czy algorytm rekomendujący konkretne rozstrzygnięcia w ogóle powinien być wykorzystywany w wymiarze sprawiedliwości, wciąż jest zbywane przez decydentów – i niestety takie systemy w Stanach Zjednoczonych zyskują na popularności. Amerykańska organizacja ACLU skutecznie przeciwstawiała się wprowadzeniu systemu szacowania ryzyka popełnienia przestępstwa w Kalifornii, ale w innych stanach USA ich liczba rośnie. W 2017 r. 25% mieszkańców USA zamieszkiwała obszary, na których je wykorzystywano, podczas gdy 4 lata wcześniej było to tylko 10%.
Zarzuty o dyskryminację pojawiają się nie tylko w odniesieniu do koloru skóry. W People's Guide To AI czytamy: Skutki działania AI dotykają wszystkich, ale – jak pokazują doświadczenia ze Stanów Zjednoczonych – w największym stopniu społeczności zmarginalizowanych – osoby o niskich dochodach, osoby o kolorze skóry innym niż biały. Właśnie te społeczności, które nie biorą dziś udziału w dyskusji na temat rozwoju technologii, są narażone na największe ryzyko związane z jej wykorzystaniem. Jakie skutki przyniesie szerokie upowszechnienie AI w miastach takich jak Detroit czy Michigan, w których 40% mieszkańców nie ma dostępu do internetu? Co oznacza dla migrantów, którzy obawiają się deportacji? Co oznacza dla osób pracujących w tych sektorach gospodarki, w których najprędzej zastąpi ich AI? Nie znamy odpowiedzi na wszystkie te pytania, ale możemy przynajmniej je postawić i zacząć szukać odpowiedzi.
Także w Polsce.
Ta twarz nie istnieje
Strona This Person Does Not Exist wyświetla w 100% realistyczne, a przy tym w 100% fałszywe zdjęcia osób. Każde odświeżenie strony generuje nowy portret. Program stworzony przez Phillipa Wanga, byłego programistę Ubera, bazuje na modelu sieci neuronowej (konkretnie: generative adversarial network – GAN). Model składa się z dwóch elementów: jeden (generator) generuje obrazy, a drugi (discriminator) odsiewa te, które wyglądają na fejki. Rywalizując ze sobą miliony razy, udoskonalają się nawzajem.
Jak podaje magazyn Inverse, fejkowe zdjęcia już dziś reklamują marki modowe i lifestyle’owe, a narzędzie może zrewolucjonizować branżę gier wideo i wszystkie inne, które wykorzystują modele 3D. Ale – jak każda technologia – narzędzie może zostać też wykorzystane do tworzenia deepfake’ów czy fałszywych profili w mediach społecznościowych, a te – do manipulowania debatą publiczną.
Z taką manipulacją mogliśmy mieć do czynienia przy okazji startu rządowej aplikacji do monitorowania interakcji społecznych ProteGO Safe, która była promowana przez zmyślonych naukowców. Z kolei jeden z banków przygotował kampanię, w której zdeepfake’ował ekoinfluencerkę Anetę Szpurę właśnie po to, żeby zwrócić uwagę na niebezpieczeństwo kradzieży tożsamości z wykorzystaniem deepfake’ów. Twórca strony This Person Does Not Exist Phillip Wang podobnie uzasadnia swoje zaangażowanie w ten projekt: opinia publiczna powinna zdawać sobie sprawę z możliwości, jakie stwarza dynamicznie rozwijająca się technologia.
VII. CYKL Ż YCIA AI I DECYZJE CZŁOWIEKA
Chcąc wyrobić sobie zdanie o algorytmie, musimy najpierw zrozumieć relację człowieka i maszyny. Każdy algorytm wiąże się z ludźmi, którzy go opracowali, a potem wdrożyli.
Na proces tworzenia AI składa się szereg decyzji podejmowanych przez człowieka, a właściwie ludzi. Ścierają się w nim opinie i wiedza: właściciela systemu, programistów, analityków danych i audytorów. Proces projektowania nie zawsze przebiega po kolei, a podejmowane w jego ramach decyzje nie zawsze są spójne. Sama AI też nie zawsze jest najlepszym narzędziem do rozwiązania problemu.
Przyjmijmy jednak, że właściciel systemu wykonał krok 0: dokonał analizy problemu, który chce rozwiązać, i – biorąc pod uwagę aktualną wiedzę technologiczną, dostępność danych oraz wstępną ocenę ryzyka, jakie taki system może wygenerować – doszedł do wniosku, że rozwiązanie powinno opierać się na modelu wykorzystującym uczenie maszynowe. Jak od tego momentu powinien wyglądać proces decyzyjny jego tworzenia?
Krok 1. Określenie celu, który ma realizować system
To najważniejsza, kierunkowa decyzja. Podejmuje ją właściciel systemu (firma, organizacja, instytucja). Określając cel, najczęściej posługuje się swoją siatką pojęciową i kieruje się własnymi wartościami.
Weźmy za przykład firmę taką jak Facebook. Jakie ma cele biznesowe, do których da się zatrudnić sztuczną inteligencję? Może na przykład chcieć, by użytkownicy spędzali więcej czasu na portalu społecznościowym i częściej klikali w sponsorowane treści, na których Facebook zarabia. Może też chcieć zatrudnić sztuczną inteligencję do automatycznego wykrywania treści, które wymagają moderacji (np. nagich ciał na zdjęciach). To różne cele, ale każdy z nich nadaje się dla uczących się algorytmów. W przypadku banku udzielającego kredytów typowym celem, do którego można zatrudnić uczący się system sztucznej inteligencji, będzie szacowanie ryzyka i odróżnianie klientów wiarygodnych od niewiarygodnych na możliwie wczesnym etapie. Dlatego analitycy finansowi od dekad trenują algorytmy w sztuce przewidywania i modelowania ludzkich zachowań.
Jeszcze inne cele przed systemem AI postawi instytucja publiczna, dla której ważne może być np. efektywne wykorzystanie środków publicznych w diagnostyce medycznej albo w obszarze pomocy społecznej. Urzędnicy mogą zatem zatrudnić algorytm do oceny, który pacjent lub klient jest najbardziej potrzebujący, ewentualnie któremu – z perspektywy budżetu państwa – najbardziej opłaca się pomóc.
Krok 2. Przetłumaczenie celu na język matematyki
Właściciel systemu, wyznaczając cel, który realizować ma sztuczna inteligencja, myśli w „swoim” języku – biznesowym, urzędowym, politycznym. Język ten sprawdzi się w wyjaśnianiu innym ludziom, po co wdrażany jest konkretny system, ale będzie niezrozumiały dla maszyny. Jeśli człowiek chce, żeby maszyna zadziałała zgodnie z jego intencjami, musi przetłumaczyć swoje cele na jej język.
Nawet uczący się model potrzebuje dokładnych instrukcji, które umożliwią mu poszukiwanie wzorców w dostarczanych danych. Nie wystarczy powiedzieć: „szukamy najpilniejszych przypadków”. Musimy precyzyjnie określić cechy pacjenta lub osoby wnioskującej o pomoc społeczną, które decydują o priorytecie zgłoszenia. Podobnie w banku: to człowiek musi określić, że liczą się dla niego np. terminowość spłat albo stabilne dochody. Żeby użyć algorytmu do utrzymywania uwagi użytkowników, Facebook również powinien określić, na czym ten stan polega: czy jedynym kryterium jest czas spędzony na portalu, czy liczy się też intensywność interakcji albo poziom pobudzenia emocjonalnego (i po czym je poznać)?
Krok 3. Czas na kompromis: co to znaczy „optymalny efekt” i jakie koszty się z nim wiążą?
Kiedy przychodzi do określenia, jakie konkretnie zadanie ma wykonać system, zwykle okazuje się, że nie da się pogodzić wszystkich potrzeb i wartości. I że konieczny będzie pewien kompromis.
W świecie, którym rządzą twarde prawa matematyki i statystyki, nie da się nagiąć algorytmu tak, żeby – po zastosowaniu do rzeczywistości – dawał tylko takie wyniki, które są politycznie poprawne albo korzystne biznesowo. Pewien margines błędu jest nie do uniknięcia. Przy czym inne skutki będzie mieć błąd na korzyść ocenianej przez AI osoby (np. przyznanie kredytu komuś, kto tak naprawdę nie jest w stanie spłacić go na czas), a inne zbyt surowa ocena (np. odrzucenie wniosku wiarygodnego klienta tylko dlatego, że miał nietypowe cechy i trafił w margines błędu). Który z tych dwóch scenariuszy powinni wybrać projektujący system?
Właśnie w tym momencie pozornie techniczne decyzje (w tym przypadku wybór tzw. funkcji straty) ujawniają swój polityczny i etyczny wymiar. Czy lepiej będzie, jeśli algorytm zatrudniony do pomocy w wymiarze sprawiedliwości zbyt nisko oszacuje ryzyko i wypuści z aresztu osobę, która drugi raz popełni przestępstwo; czy jeśli pomyli się w drugą stronę i zatrzyma w nim osobę, która tego nie zrobi? Czy lepiej będzie, jeśli model wspierający diagnostykę raka zmarnuje trochę publicznych pieniędzy na leczenie zmian nowotworowych (w drodze niepozbawionej skutków ubocznych terapii), które wcale nie okazały się złośliwe; czy jeśli przez wąsko skalibrowane sito nie przejdzie jedna osoba wymagająca pilnej pomocy?
Każda decyzja w projektowaniu systemów AI ma swój koszt. Nie da się zaprojektować systemu w taki sposób, by wyeliminować lub nawet zminimalizować jednocześnie oba typy błędów: wskazania fałszywie negatywne (false negatives) i fałszywie pozytywne (false positives). O tym, który typ błędów ma prawo zdarzyć się częściej, zawsze decyduje człowiek. Najlepiej jeśli zrobi to właściciel systemu w dialogu z analitykiem danych po przeanalizowaniu konsekwencji każdej z rozważanych możliwości – w konsultacji z osobami, których te decyzje dotkną.
Krok 4. Wybór zestawu danych treningowych
Tak jak mózg potrzebuje tlenu, sztuczna inteligencja potrzebuje danych. To na nich uczy się zależności i szuka nowych rozwiązań dla zadanych jej problemów. Przy czym ważna jest nie tylko ilość danych, ale też ich jakość i adekwatność. Jak głosi powtarzana wśród analityków danych maksyma: garbage in, garbage out (śmieci na wejściu, śmieci na wyjściu). Model statystyczny nakarmiony bezwartościowymi, nieadekwatnymi danymi będzie bezużyteczny.
Skąd wziąć dane odpowiednie do celu, jaki postawił przed systemem właściciel? Idealny zestaw danych to nawet świecie big data biały kruk. Zwykle analitycy muszą włożyć realny wysiłek w przygotowanie danych, które udało im się pozyskać, do trenowania. A po drodze podejmują szereg ważnych decyzji.
W pierwszej kolejności oceniają źródła danych, z których zamierzają skorzystać. Które z nich są legalne, rzetelne i dają adekwatny obraz rzeczywistości? Czy warto dokupić zbiór danych opisujący jakiś fragment rzeczywistości, którego im brakuje, czy lepiej dostosować cel stawiany przed AI do takiego, dla którego mają zestaw pewnych, dostępnych zgodnie z prawem danych?
Analitycy powinni umieć uzasadnić, dlaczego do trenowania modelu wybrali akurat ten, a nie inny zestaw danych. Na jakie cechy osób (obiektów) opisywanych przez dane zwrócili uwagę? Jak ocenili poprawność, aktualność i reprezentatywność danych? Jaką metodą odsiali dane niekompletne, nieaktualne albo w inny sposób zanieczyszczone? Powinni też przewidzieć i zawczasu skorygować skrzywienie (data bias), które pojawiło się w zestawie danych w wyniku ludzkich uprzedzeń (np. dane o osobach wybranych w rekrutacji odzwierciedlają uprzedzenia i preferencje rekruterów) lub występujących nierówności (np. surowsze wyroki wśród Afroamerykanów niż wśród białych mieszkańców USA).

Krok 5. Wybór modelu statystycznego odpowiedniego do założonego celu
Projektanci systemów wykorzystujących AI rzadko tworzą własne modele statystyczne. Taniej i prościej jest dostosować model już istniejący. Jednak sam wybór modelu odpowiedniego do celu, który ma realizować system, a następnie dostosowanie jego parametrów do danego kontekstu też jest realnym wyzwaniem. Często wymaga to kilku podejść, a przede wszystkim uczciwej ewaluacji (o której niżej).
Jak zatem wybrać odpowiedni model? Przede wszystkim trzeba zwrócić uwagę na jego przeznaczenie. W rozpoznawaniu wzorców na obrazach (np. skanach ludzkiego ciała w ramach diagnostyki medycznej) sprawdzi się konwolucyjna sieć neuronowa. Do szacowania ryzyka w oparciu o wcześniejsze doświadczenia i wzorce zaobserwowane w danych (np. historii kredytowej klientów banku) lepiej sięgnąć po model proporcjonalnego hazardu czy regresję logistyczną.
W kolejnych krokach analitycy danych będą musieli – często metodą prób i błędów – dopasować parametry modelu (czyli elementy podlegające zmianie) do specyfiki zadania i do konkretnego kontekstu. Najważniejsze są dane, na których model ma pracować: najpierw w fazie testowania, a następnie w docelowym środowisku. Jeśli dane są niekompletne, niereprezentatywne lub „skrzywione” (np. zapisane są w nich zależności odpowiadające dyskryminacji ze względu na płeć lub kolor skóry), bez wprowadzenia odpowiedniej korekty również model będzie dawał nietrafione wyniki.
Na tym etapie analitycy danych określają też czynniki, które mają znaczenie dla skuteczności działania modelu. Na przykład jeśli zadanie polega na odróżnieniu, czy osoba na zdjęciu się uśmiecha, czy wykazuje inną emocję, w procesie uczenia maszynowego znaczenie będą miały takie czynniki, jak płeć i wiek osoby, oświetlenie, pogoda (np. gęstość powietrza) i rozdzielczość zdjęcia (osobną kwestią jest to, czy w ogóle taki system się sprawdzi, skoro emocje są zapisane nie tylko w wyrazie twarzy, a sposób ich wyrażania zależy i od czynników społeczno-kulturowych, i od temperamentu danej osoby).
Krok 6. Testowanie, czy wybrany model działa prawidłowo
Każdy model przed zastosowaniem do rzeczywistych przypadków powinien zostać przetestowany. Do tego potrzebny jest nowy zestaw danych – innych niż te, na których model się uczył zależności – oraz ustalone mierniki błędów (bo pewien margines błędu jest nie do uniknięcia). Projektanci zazwyczaj skupiają się na tych metrykach błędów, które są najbliżej związane z celem, jakie ma realizować AI.
Na przykład przy ewaluacji modeli, które mają przypisywać ludzi (lub inne obiekty) do pewnych kategorii (klasyfikacja), analityk powinien zwrócić uwagę na dokładność (accuracy), precyzję (precision), czułość (recall), a także na to, jaka część wskazań jest fałszywie pozytywna (False Positive Rate) i fałszywie negatywna (False Negative Rate), jaki jest stosunek wskazań fałszywie pozytywnych do sumy wskazań pozytywnych (False Discovery Rate) i jaki jest stosunek wskazań fałszywie negatywnych do sumy wskazań negatywnych (False Omission Rate). Do ewaluacji modeli wykorzystujących inną metodę statystyczną, np. regresję, wykorzystuje się inne mierniki błędów.
Poniższa tabelka ilustruje cztery możliwe sytuacje, w zależności od rodzaju pojawiających się błędów:
| Stan faktyczny | Razem | |||
|---|---|---|---|---|
| chory | zdrowy | |||
| wynik klasyfikacji | chory (wynik testu pozytywny) | TP: prawidłowa decyzja pozytywna | FP (błąd I typu: wynik fałszywie pozytywny) | P' |
| zdrowy (wynik testu negatywny) | FN (błąd II typu: wynik fałszywie negatywny) | TN: prawidłowa decyzja negatywna | N' | |
| Razem | P | N | ||
Legenda:
TP: true positive, hit
TN: true negative, correct rejection
FP: false positive, false alarm
FN: false negative, with miss
Źródło: Uczenie maszynowe i sztuczne sieci neuronowe. Wykład: Ocena jakości klasyfikacji
Wyniki testów powinny dać odpowiedź na następujące pytania:
- Jak często model daje prawidłowy wynik? Jak często się myli?
- Czy wykryte błędy dotykają jednych grup osób w większym stopniu niż innych ludzi (np. wskazania błędne dotyczą częściej kobiet niż mężczyzn)?
- Czy model rozwiązuje dokładnie to zadanie, które zostało przed nim postawione, czy też w procesie trenowania sam je zmodyfikował (np. rozpoznaje na zdjęciach tło zamiast uwidocznionych na nim zwierząt)?
- Czy w swoich wskazaniach pomija pewne grupy bądź kategorie przypadków lub stawia wyższe wymagania kwalifikowalności dla pewnych grup bądź kategorii przypadków? (Przykładowo: po przeprowadzeniu ewaluacji okazało się, że w amerykańskich szpitalach korzystających ze wsparcia AI osoby czarnoskóre były traktowane jako mniej potrzebujące niż osoby białe – cierpiące na te same choroby – tylko dlatego, że na ich leczenie wydawano mniej pieniędzy).
Krok 7. Wnioski z testów – co trzeba poprawić?
Może się okazać, że wytrenowany model myli się tak często, że jego zastosowanie do rzeczywistych przypadków nie przyniesie wymiernych korzyści (równie trafnie, a taniej, byłoby rzucić monetą); albo że nauczył się wątpliwych korelacji (np. rozpoznaje zwierzęta na zdjęciach w oparciu o cechy tła, a nie samego zwierzęcia); albo że nie jest w stanie rozwiązać postawionego mu zadania (np. dobrze się sprawdza w analizie obrazowych wyników badań i z dużą trafnością rozpoznaje chorobowo zmienioną tkankę, ale formułuje błędne zalecenia terapeutyczne dla pacjenta). Jeśli z testów płynie taki wniosek, właściciel systemu ma kilka możliwości:
- wrócić do kroku 5 i wybrać inny, bardziej odpowiedni do zadania model statystyczny;
- wrócić do kroku 4 i zmienić (uzupełnić, wyczyścić, lepiej opracować) dane, na których model został wytrenowany;
- cofnąć się do samego początku i przemyśleć cel i sens systemu. Czy AI w ogóle nadaje się do rozwiązania postawionego problemu? A może sam problem został źle sformułowany? Powrót do punktu wyjścia jest najtrudniejszą decyzją, ale czasem najbardziej opłacalną.
Załóżmy jednak, że testy się powiodły i projekt jest dalej rozwijany. Właściciel systemu – w dialogu z analitykami danych – może teraz zadecydować, czy (i jakie) zmiany w parametrach modelu trzeba jeszcze wprowadzić, żeby skorygować liczbę i typ występujących błędów.
Jak wspominaliśmy wcześniej, nie da się wyeliminować wszystkich błędów. Jedyne, co mogą (a nawet powinni) zrobić właściciel systemu i analitycy danych, to zdecydować, które błędy będą tolerować, a których nie. Ta decyzja powinna wynikać z charakteru systemu i skutków, jakie dany typ błędu może wywołać w realnym świecie. Na przykład model używany w diagnostyce medycznej do odsiewania pacjentów, którzy są zdrowi, powinien mieć wysoką czułość (identyfikować wszystkie chore osoby, nawet jeśli oznacza to niepotrzebną klasyfikację części zdrowych osób jako chore), nawet kosztem precyzji. Jak widać na tym przykładzie, sposób skalibrowania modelu statystycznego może mieć istotne etyczne (a często również polityczne, społeczne i finansowe) konsekwencje. Dlatego ostatecznie wybrane parametry powinny być jawne, a w przypadku modeli stosowanych przez władze publiczne – wręcz poddane pod otwarte konsultacje.
Kontrowersje wokół komercyjnych zastosowań AI
Polska administracja publiczna nie korzysta z AI w takim stopniu jak amerykańska. Na każdym kroku spotykamy ją jednak w zastosowaniach komercyjnych – i nawet na tym polu nie obywa się bez kontrowersji. O asystentach głosowych (Alexa, Google Home, Siri) zrobiło się głośno, kiedy okazało się, że nagrania poleceń głosowych (i wszystkiego, co „usłyszą” przy okazji) trafiają do producentów (Amazona, Google’a i Apple’a), a proces uczenia maszynowego jest intensywnie wspomagany przez słuchających tych nagrań pracowników cyberkorporacji.
Algorytm rekomendacyjny YouTube’a ma na celu utrzymanie uwagi odbiorcy, ale już nie bierze pod uwagę jakości tego, co pokazuje (ani bezpieczeństwa użytkownika). Kilka kliknięć od odcinka Psiego patrolu dziecko trafia na przeróbkę, w której bohaterowie ulubionej bajki przedszkolaków próbują popełnić samobójstwo przy hipnotyzującej muzyce. W ramach dbania o wizerunek marki wiele firm wycofuje się z platformy – np. Samsung, Warner Bros, L’Oreal czy Danone, które w ten sposób sprzeciwiły się wyświetlaniu reklam ich produktów na filmach negujących zmiany klimatyczne.
Kontrowersje i zainteresowanie organów ochrony konkurencji wyszukiwarką Google’a wzbudza przede wszystkim to, że w wynikach wyszukiwań wysoko wyświetlają się produkty i strony należące do tej firmy, jej spółek córek i partnerów.
Czarnym charakterem wśród komercyjnych zastosowań AI jest jednak niewątpliwie newsfeed Facebooka, a to dzięki ogromnemu potencjałowi manipulowania ludźmi (od ich nastrojów i zachowań konsumpcyjnych po wybory polityczne) oraz zarzutom, że spersonalizowany newsfeed zamyka użytkowników i użytkowniczki w bańkach informacyjnych. To z kolei może prowadzić do radykalizacji poglądów i wzmacniać podatność na dezinformację.
VIII. AI JAKO ZASŁONA DYMNA DLA DECYZJI POLITYCZNYCH
Algorytm predykcyjny staje się szczególnie niebezpieczny, kiedy spełnia trzy warunki: jest ważny, tajny i destrukcyjny.
Prof. Rhema Vaithianathan uważa, że AI powinna zastąpić biurokrację: jej decyzje będą natychmiastowe, spójne i przede wszystkim apolityczne. Jednak zdaniem innej badaczki, Virginii Eubanks, zastąpienie urzędników apolityczną sztuczną inteligencją będzie de facto oznaczało schowanie polityki w czarnej skrzynce: Łatwo będzie zapomnieć, że za stworzeniem tejże apolitycznej sztucznej inteligencji stały całkiem polityczne decyzje ludzi, a tak brzemienne w skutki decyzje, jak umożliwienie wyjścia z aresztu za kaucją czy odebranie dziecka rodzicom, zostaną ukryte za fasadą obiektywizmu.
Pokusa uchylenia się od odpowiedzialności – poprzez przerzucenie jej na tzw. system (najczęściej w tej roli wystąpi „czarna skrzynka”) – jest ogromna, i to zarówno w świecie polityki, jak i w biznesie. Zwłaszcza gdy w grę wchodzą niepopularne lub moralnie trudne decyzje. A przecież nawet system działający na zasadzie „czarnej skrzynki” realizuje cele i odzwierciedla wartości, jakie zakodował w nim człowiek.
Ujawnione w ostatnich latach – i opisane wyżej – przypadki wykorzystania dyskryminujących algorytmów przez firmy i instytucje publiczne są wystarczającym powodem, żeby zachować ostrożność. Dużo napisano o ich negatywnym wpływie, ale o kluczowych decyzjach, jakie podejmowali projektanci tych systemów – wyborze danych, modelu czy funkcji straty – wciąż wiemy niewiele. Tymczasem to, jak system wpływa na ludzi, zależy właśnie od tego, jakie decyzje zapadły w procesie jego tworzenia.
Tłumaczenie złożonych społecznych problemów na język matematyki siłą rzeczy wymaga uproszczeń, milczących założeń i kompromisów. Mierniki sukcesu dla sztucznej inteligencji odbiegają od tego, jak sukces wyobrażają sobie ludzie – którzy dodatkowo często różnią się w tej ocenie między sobą. Kluczem do przejrzystości i rozliczalności AI jest wyciąganie na światło dzienne tych wszystkich ograniczeń i założeń, jakie zostały utrwalone w parametrach modelu statystycznego. Jedynie mając tę wiedzę, możemy o nich dyskutować w otwartej, demokratycznej debacie.
Konsekwencje decyzji ukrytych za tajnym algorytmem ponosi zwykły człowiek
Gubernator Arizony ogłosił na początku maja, że po czasowym lockdownie spowodowanym pandemią koronawirusa czas ruszyć z odmrażaniem gospodarki. Swoją decyzję podparł prognozą wydaną przez „pandemiczny model predykcyjny” Federalnej Agencji Zarządzania Kryzysowego (Federal Emergency Management Agency). W tym samym czasie z obliczeń alternatywnego modelu, przygotowanego przez naukowców, wynikało, że lepiej odczekać z otwieraniem gospodarki przynajmniej do końca maja, żeby zapobiec dalszemu obciążaniu już niewydolnej służby zdrowia.
Algorytm, na podstawie którego gubernator Arizony podjął decyzję o rozpoczęciu odmrożenia już 8 maja, spełnia kryteria „niebezpiecznego” sformułowane przez Cathy O’Neil: przekonał ważnego urzędnika do podjęcia decyzji mającej konsekwencje dla 7 milionów mieszkańców Arizony, sposób jego działania pozostaje tajemnicą, a skutki dla ludzi mogą być tragiczne. Cathy O’Neil podkreśla, że zastępowanie publicznej debaty na temat tak ważnych politycznych decyzji tajnym, pseudomatematycznym narzędziem to nic innego jak ucieczka przed polityczną odpowiedzialnością za kontrowersyjne decyzje, których konsekwencje poniosą – jak zawsze – zwykli ludzie.
Jak pisze Piotr Fortuna w Dwutygodniku: rozmawiając o sztucznej inteligencji, musimy pamiętać, że algorytmy uczenia maszynowego posługują się logiką instrumentalną – operują wyłącznie w obrębie wyznaczonych celów. W związku z tym zawsze powinniśmy zadawać pytanie: „Jakim interesom służą?”.
IX. WARTO PRZECZYTAĆ
- AI Blindspot, A Discovery Process for preventing, detecting, and mitigating bias in AI systems
- COE, Unboxing artificial intelligence: 10 steps to protect human rights
- Fundacja Panoptykon, Co zawiera algorytm służący do profilowania w urzędach pracy?
- ICO, Explaining decisions made with AI. Draft guidance for consultation. Part 2
- MIT Technology Review, What is AI? We drew you a flowchart to work it out
- New York Times, Algorithms Learn Our Workplace Biases. Can They Help Us Unlearn Them?
- New York Times, Wrongfully Accused by an Algorithm
- ProPublica, Machine Bias. There’s software used across the country to predict future criminals. And it’s biased against blacks
- Sztuczna Inteligencja, Pokaż selfie maszynie. Powie ci, jaki jesteś
- Vice, Companies are using AI to stop bias in hiring. They could also make discrimination worse
- Wired, A Sobering Message About the Future at AI's Biggest Party
- Barocas Solon, Hardt Moritz, Narayanan Arvind, Fairness and machine learning. Limitations and Opportunities, 2020
- Fry Hannah, Hello world. Jak być człowiekiem w epoce maszyn, Wydawnictwo Literackie, 2019
- Green Ben, The False Promise of Risk Assessments: Epistemic Reform and the Limits of Fairness, 2020
- Harrison Galen, Hanson Julia, Jacinto Christine, Ramirez Julio, Ur Blase, An empirical study on the perceived fairness of realistic, imperfect machine learning models, 2020
- Marks Mason, Artificial Intelligence Based Suicide Prediction (early draft version), 2019
- Narayanan Arvind, How to recognize AI snake oil, 2019
- Obermeyer Ziad, Powers Brian, Vogeli Christine, Mullainathan Sendhil, Dissecting racial bias in an algorithm used to manage the health of populations, Science, 2019
- O’Neil Cathy, Broń matematycznej zagłady, Wydawnictwo Naukowe PWN, 2017
- Onuoha Mimi, Nucera Diana, A People's Guide To AI, 2018
- Przegalińska Aleksandra, Oksanowicz Paweł, Sztuczna inteligencja. Nieludzka, arcyludzka, Wydawnictwo Znak, 2020
Opracowanie: Anna Obem, Katarzyna Szymielewicz
Współpraca merytoryczna: Agata Foryciarz
Korekta: Urszula Dobrzańska
Projekt i wykonanie strony: Marta Gawałko | Caltha
Licencja: CC BY SA 4.0 (z wyłączeniem schematu Czym jest AI? © MIT technology Review)
Organizacja publikująca: Fundacja Panoptykon, 2020
Serdecznie dziękujemy Arturowi Domosławskiemu za inspirację i użyczenie pomysłu na tytuł publikacji (Kapuściński non-fiction, wyd. Świat Książki, 2010).
Materiał powstał dzięki wsparciu Samsung Electronics Polska.